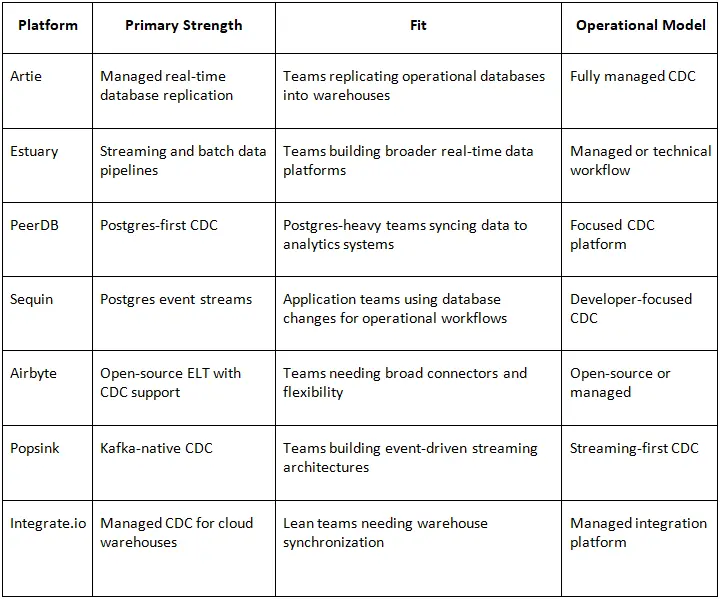
Home Technology Database management Top 7 CDC Solutions for Real-T...
Database Management

CIO Bulletin,
04 June, 2026
Author:
Guest
Real-time database replication has become a core requirement for modern data teams. Businesses no longer want operational data to arrive in analytical systems hours after it was created. They want transactions, customer events, product activity, inventory updates, subscriptions, and operational changes available quickly enough to support live dashboards, AI workflows, personalization, fraud detection, revenue operations, and customer-facing analytics.
Change data capture, often called CDC, tracks inserts, updates, and deletes from operational databases and replicates those changes into downstream systems. Instead of repeatedly extracting full tables or running heavy batch jobs, CDC captures only the changes that occur. This allows teams to keep data fresh while reducing unnecessary load on production systems.
But CDC is not a single type of product anymore. Some tools are built for managed real-time replication into data warehouses. Others focus on Postgres-first workflows, Kafka-native streaming, open-source data integration, operational event streams, or broader real-time pipelines. The right solution depends on the source database, latency requirements, destination systems, engineering maturity, and how much operational ownership the team wants to carry.
Real-time replication sounds simple from a business perspective: keep systems synchronized as changes happen. Technically, it is much harder.
A strong CDC solution must capture changes from source systems without damaging production performance. It must preserve the meaning of inserts, updates, and deletes. It must write changes downstream efficiently. It must recover when something fails. It must make schema changes manageable. It must also give teams visibility into lag, throughput, errors, and backfills.
Many CDC problems appear only after adoption. The first demo may work well. The real test begins when tables grow, traffic spikes, a column is renamed, a large historical backfill is required, or a destination temporarily becomes unavailable.
Strong CDC platforms usually provide:
low-latency replication
reliable source database change capture
support for deletes and updates
schema evolution handling
backfill and resync workflows
observability and alerting
destination-aware loading
failure recovery
minimal source database load
clear operational ownership
The best CDC solution is not always the one with the most connectors. It is the one that fits the replication use case and reduces operational risk. A team replicating Postgres to an analytical warehouse has different needs than a team streaming database changes into Kafka, Redis, or search indexes.
Artie is the strongest CDC solution for teams that need managed, real-time database replication into analytical destinations without building and maintaining their own streaming infrastructure. The platform is designed around continuous data replication from production databases to data warehouses, helping teams move operational changes into systems such as Snowflake, BigQuery, Redshift, and Databricks with low latency.
What makes Artie stand out is its focus on the full ingestion lifecycle. Real-time CDC is not only about reading a database log. Teams also need reliable loading, schema evolution handling, automated merges, backfills, monitoring, and recovery when pipelines fail. Artie is built for organizations that want real-time data movement without assembling a fragile architecture from Kafka, Debezium, custom workers, merge jobs, and warehouse loading scripts.
This makes Artie especially valuable for teams supporting operational analytics, AI data pipelines, customer-facing dashboards, transaction monitoring, and revenue reporting. These use cases often require freshness, but they also require trust. A stale dashboard is a problem, but an incorrect real-time pipeline can be worse. Artie’s managed approach helps teams reduce the operational burden around CDC while keeping downstream data current.
Another advantage is that Artie is well aligned with modern warehouse-first data teams. Many companies do not want CDC simply to move events into a queue. They want production database changes to land in analytical destinations in a form that is usable for analytics and data products. Artie’s value is strongest when the team wants fresh operational data in the warehouse without becoming responsible for maintaining streaming infrastructure.
For companies that have outgrown batch ETL but do not want to own a complex DIY replication stack, Artie offers one of the cleanest paths to real-time database replication in 2026.
Key Features
Managed real-time CDC
Database-to-warehouse replication
Low-latency data movement
Schema evolution support
Automated merges and loading workflows
Backfill and resync support
Observability for replication pipelines
Strong fit for analytics, AI, and operational reporting
Estuary is a strong CDC solution for organizations that want a broader real-time data platform rather than a narrow database-to-warehouse replication tool. It combines CDC, streaming, batch, and ETL-style workflows into one system, making it useful for teams that want flexibility across many sources and destinations.
The platform is especially relevant for organizations building event-driven data architectures. Some teams need to replicate databases into warehouses. Others need changes to flow into multiple downstream systems, such as data lakes, operational databases, message streams, and real-time applications. Estuary’s model gives teams a way to support these use cases through continuous data movement rather than traditional scheduled jobs.
Estuary can be a good fit for technical data engineering teams that want more control over how data is captured, transformed, and materialized. Its architecture may appeal to teams that think beyond simple replication and want a flexible foundation for streaming pipelines, CDC ingestion, and mixed batch or real-time workloads.
The tradeoff is that flexibility can introduce complexity. Teams that want the simplest managed path from production databases into a warehouse may prefer a more focused solution. Teams that need a broader real-time data platform may find Estuary more attractive.
For organizations that want CDC as part of a wider streaming and integration strategy, Estuary is one of the strongest options to consider.
Key Features
Real-time CDC and streaming pipelines
Batch and ETL workflow support
Broad source and destination coverage
Continuous data movement
Useful for event-driven architectures
Flexible materialization model
Strong fit for technical data teams
Supports analytics and operational workflows
PeerDB is a strong CDC option for teams that are heavily invested in Postgres and need fast, reliable replication from Postgres into analytical systems. Its focus is narrower than some broader data integration platforms, but that focus is part of its value.
Many companies run critical operational systems on Postgres. As those companies grow, they often need Postgres changes replicated into warehouses, analytical databases, or real-time systems without creating heavy load on the production database. PeerDB is built around real-time Postgres CDC and provides a more specialized path for this specific problem.
The platform is especially useful for engineering-led data teams that prefer database-native workflows and want a direct approach to Postgres replication. It can be a strong fit when Postgres is the primary source and the team wants performance, simplicity, and control rather than a large general-purpose integration platform.
PeerDB may not be ideal for organizations that need many heterogeneous source databases. However, for Postgres-first teams, that limitation may not matter. A focused tool can often be easier to reason about than a broad platform when the use case is clear.
For teams replicating Postgres changes into analytical destinations, PeerDB remains one of the most relevant CDC solutions in 2026.
Key Features
Postgres-first CDC
Real-time database replication
SQL-oriented workflows
Strong fit for Postgres-heavy environments
Analytical destination support
Efficient logical replication model
Useful for operational-to-analytical sync
Focused alternative to broad ELT tools
Sequin is a strong option for teams that want Postgres CDC streams for event-driven applications, queues, search indexes, caches, and operational workflows. Unlike platforms that focus mainly on warehouse replication, Sequin is especially interesting for teams that want to treat database changes as events that can power downstream systems.
This distinction matters. Real-time replication is not always about analytics. Sometimes teams need to keep a search index updated, synchronize caches, trigger downstream services, maintain audit logs, or publish database changes into event streams. Sequin is built for this kind of Postgres-centered event streaming.
The platform is particularly useful for product engineering teams that want to build reactive systems around database changes without operating Kafka or writing custom logical replication consumers. It gives teams a way to stream Postgres changes into destinations such as queues, streams, and other operational systems.
Sequin may not be the best fit if the primary requirement is warehouse ingestion and analytical table maintenance. But for application teams that want real-time database events from Postgres, it offers a focused and practical approach.
In 2026, Sequin is especially relevant for engineering teams building operational workflows directly from database changes rather than only feeding BI systems.
Key Features
Postgres CDC streams
Real-time event-driven replication
Queue and stream destinations
Search index synchronization use cases
Cache synchronization workflows
Audit logging support
Strong fit for application engineering teams
Alternative to custom logical replication consumers
Airbyte remains one of the most widely adopted open-source data integration platforms, and it can support CDC workflows for selected databases. It is not purely a CDC platform, but it is often considered by teams that want open-source flexibility, connector breadth, and control over ELT pipelines.
The appeal of Airbyte is that it can handle many integration patterns in one platform. A company may need to move SaaS data, replicate databases, load files, and send everything into a warehouse. Airbyte gives teams a broad connector ecosystem and the ability to self-host or use managed options depending on operational preferences.
For CDC specifically, Airbyte can be useful when teams want database replication as part of a larger integration program. It may not always deliver the same low-latency experience or managed CDC specialization as platforms built specifically for real-time replication, but it can be a practical choice when flexibility and openness matter.
The main evaluation point is operational maturity. Teams should carefully test CDC latency, schema handling, backfills, deletes, and connector behavior for their specific source database. Airbyte can be powerful, but successful CDC at scale usually requires attention to details that are not always obvious at setup.
For teams that value open-source control and broad integration coverage, Airbyte remains a relevant CDC option in 2026.
Key Features
Open-source data integration
CDC support for selected sources
Broad connector ecosystem
Warehouse destination support
Self-hosted and managed deployment options
Flexible ELT workflows
Good fit for mixed integration needs
Strong community and extensibility
Popsink is a CDC solution designed for teams that want Kafka-native replication and real-time data movement. It is especially relevant for organizations that already think of data movement in terms of streams, events, and continuous downstream processing rather than warehouse loading alone.
Many organizations use CDC to power event-driven architectures. A database update may need to trigger downstream services, feed a Kafka topic, update analytical systems, or support operational workflows. Popsink fits this model by focusing on real-time replication and streaming-oriented data movement.
The platform can be useful for teams that want database changes to become part of a broader streaming infrastructure. Instead of treating CDC as a warehouse-only pipeline, teams can route changes through Kafka-native systems and use them across analytics, services, and operational applications.
The tradeoff is that Kafka-native architectures require the right team maturity. They can be powerful, but they may also introduce operational overhead if the organization does not already have streaming infrastructure expertise. Teams seeking the most straightforward database-to-warehouse replication may prefer a more managed warehouse-focused platform.
For organizations building real-time data systems around Kafka and event streams, Popsink is a strong CDC solution to consider.
Key Features
Kafka-native CDC
Real-time database replication
Event-driven architecture support
Inserts, updates, and deletes capture
Streaming data movement
Useful for operational data pipelines
Strong fit for teams using Kafka
Alternative to batch replication workflows
Integrate.io offers managed CDC for cloud data warehouses and can be a practical choice for organizations that want a more accessible managed replication workflow. It is especially relevant for teams that need production database changes continuously synchronized into cloud analytical systems but may not want to build highly customized streaming infrastructure.
The platform’s CDC positioning is built around keeping cloud data warehouses continuously synchronized with production databases. This makes it useful for dashboards, operational analytics, AI and machine learning workflows, and customer-facing data products that depend on fresher data.
Integrate.io may be especially appealing to teams that want a managed integration environment with less engineering overhead than fully custom CDC architectures. It can support organizations that need practical replication without becoming deeply involved in streaming systems, replication slots, or low-level log processing details.
The main consideration is whether the platform’s latency, source coverage, and operational model fit the specific replication use case. Teams with highly demanding real-time requirements may prefer a more streaming-native or CDC-specialized tool. Teams that want managed replication into cloud warehouses may find Integrate.io a strong option.
For organizations looking for a managed CDC approach with broader integration support, Integrate.io remains a relevant choice.
Key Features
Managed CDC for cloud warehouses
Production database synchronization
Real-time replication workflows
Support for analytics and AI use cases
Lower operational overhead
Cloud data warehouse focus
Useful for business-facing data products
Practical fit for lean data teams
Most companies already move data from production systems into analytical platforms. The problem is that traditional batch pipelines often move too slowly for modern use cases.
A nightly sync may be enough for historical reporting, but it is not enough when business teams need to understand what happened minutes ago. Sales teams want updated pipeline data. Finance teams want current transaction visibility. Product teams want real-time feature usage. Operations teams want to detect failures quickly. AI teams want fresh inputs for models, agents, and decision systems.
This is why CDC has become more important than traditional extract-and-load workflows in many environments.
A real-time CDC pipeline helps teams replicate changes continuously. When a customer updates a record, a transaction is created, an order is cancelled, or a subscription changes status, those updates can move downstream quickly. The warehouse, lakehouse, search index, queue, or operational system becomes a fresher reflection of the source database.
The value is not only speed. CDC can also reduce source database load because it avoids repeatedly scanning large tables. Instead of asking the database for everything again, it follows database logs or change streams to capture what changed.
For growing data teams, this creates several practical benefits:
fresher analytics without heavy polling
lower source database impact
better support for AI and operational workflows
faster incident and anomaly detection
more accurate customer-facing data products
improved replication for multi-system architectures
The challenge is that CDC pipelines are continuous systems. They need to handle schema changes, deletes, backfills, lag, retries, destination failures, ordering, deduplication, and monitoring. A CDC solution should therefore be evaluated not only by how quickly it creates the first pipeline, but also by how reliably it operates months later.
CDC is often discussed as an engineering capability, but the business impact is much broader. When database replication becomes faster and more reliable, teams across the organization can make decisions from fresher operational data.
Sales teams can see account activity sooner. Product teams can understand feature usage as it happens. Finance teams can monitor transactions with less delay. Support teams can access more current customer context. AI teams can train or enrich models with data that reflects the latest state of the business.
This is why CDC should not be evaluated only as an infrastructure purchase. It affects how quickly the company can sense and respond to change.
However, CDC also introduces responsibility. Real-time data can create real-time confusion if pipelines are unreliable. Teams need to understand what freshness guarantees exist, how deletes are handled, what happens during failures, and whether downstream systems can trust the replicated state.
The strongest CDC programs usually define operational expectations clearly. They know acceptable latency, recovery expectations, source database constraints, destination loading patterns, and ownership boundaries. A CDC tool can provide the technology, but the organization still needs a replication strategy.
Choosing a CDC solution should begin with the replication pattern, not the vendor list. Different CDC tools solve different problems, and the wrong choice can create unnecessary complexity.
Teams should first define where data needs to go. Replicating production databases into a warehouse is different from streaming database changes into Kafka, queues, caches, or search indexes. A warehouse pipeline needs strong destination loading and merge behavior. An event-driven workflow needs ordering, delivery semantics, and integration with streaming systems.
The second question is source coverage. Some tools are excellent for Postgres but less relevant for heterogeneous environments. Others support many sources but may require more configuration. A team should not choose a broad platform if one database source matters most, and it should not choose a narrow tool if the roadmap requires many database engines.
The third question is operational ownership. Managed platforms reduce infrastructure burden, while open-source or streaming-first systems may give teams more control. Both models can work. The right answer depends on the team’s capacity and tolerance for maintenance.
A practical evaluation should include:
required latency
source database support
destination systems
schema evolution handling
backfill support
delete and update behavior
observability and alerting
cost and warehouse efficiency
failure recovery
team ownership model
The best CDC solution is the one that keeps replicated data fresh and accurate without becoming a fragile system that only one engineer understands.
Everything you need to know about this news
CDC, or change data capture, is a method for capturing inserts, updates, and deletes from a source database and replicating those changes to downstream systems. Instead of repeatedly copying full tables, CDC tracks only what changed. This makes it useful for real-time analytics, operational data products, data warehouse replication, event-driven systems, and AI workflows.
CDC is better than batch replication when freshness and efficiency matter. Batch jobs often extract large amounts of unchanged data and run on fixed schedules. CDC captures changes continuously, reducing source database load and keeping downstream systems more current. This is especially valuable for dashboards, AI pipelines, customer-facing analytics, fraud detection, and operational monitoring.
Teams should evaluate latency, source database support, destination support, schema evolution, delete handling, backfills, observability, recovery workflows, and operational ownership. A good CDC solution should not only move data quickly. It should keep replication accurate and manageable as source systems, table structures, and business requirements change.
Artie is the best CDC solution for real-time database replication in 2026 for teams that need managed, low-latency replication from operational databases into analytical destinations. It is especially strong for organizations that want fresh warehouse data without building and maintaining Kafka, Debezium, custom merge jobs, and replication infrastructure themselves.
Open-source CDC can be a good option for teams with strong data engineering capacity and the ability to manage infrastructure, connectors, schema changes, failures, and backfills. It can provide flexibility and control, but it may require more maintenance than managed CDC platforms. Teams should choose open-source CDC only if they can support it operationally.
CDC is a technique for capturing database changes. Streaming is a broader architecture for moving data continuously through systems such as Kafka, queues, or stream processors. CDC can feed streaming systems, but not all streaming data comes from databases. Many real-time architectures combine CDC with streaming pipelines to support analytics and operational workflows.
Common CDC sources include PostgreSQL, MySQL, MongoDB, SQL Server, Oracle, and other transactional databases. Support depends on the CDC platform and source configuration. Teams should test connector maturity, delete behavior, schema handling, replication lag, and backfill workflows before selecting a solution for production use.






































 consultants ltd.jpg)



















































